Neural Nets: Hyperparameter tuning on tabular data
Motivation
Most of the talk in Deep Learning is on either NLP or image recognition. These are all interesting cases in and by itself, however most of the business cases usually do not revolve around these topics. You can use many of the techniques already established from NLP or image recognition, still there are a few differences on how to better make use of Deep Learning on tabular data. This article should stress out these differences and share some insights on what works for Deep Learning on tabular data and what not.
In my experience a great deal of business-relevant cases is based on tabular data, e.g. fraud detection, which vouchers to use for which customer, when to send an email etc. Many of these topics are handeled by linear regressions or tree based models.
Still, these use cases can heavily benefit from deep learning and be used in ways tree based algoritms do not work. For example, a tree based approach does a terrible job at extrapolating.
Let me give you an example. We want to predict how much the customer will spend given the received voucher. So far we have been sending vouchers for either 10% or 20%. We now use our tree based model and the results are looking just fine. But suddenly one of your email colleagues has the mad idea of sending a voucher of 15%. How much would a customer buy given we send her this voucher. The answer your tree-based model will give is the same result the 10% voucher will give (or the 20% voucher, depending on your trained model). It simply cannot extrapolate on data it has never seen.
The experiment
Deep Learning to the rescue. My colleague and I were working on a task to predict spending of a customer given a specific voucher. We wanted to better understand what works for neural networks on tabular data and therefore look at different hyperparameters and how they effect the quality of the model. In detail, we looked at the batch size, learning rate, epochs, and the architecture of the neural net.
The target value was how much the customer has spent after receiving an email with a specific voucher. We built a neural net looking like this:

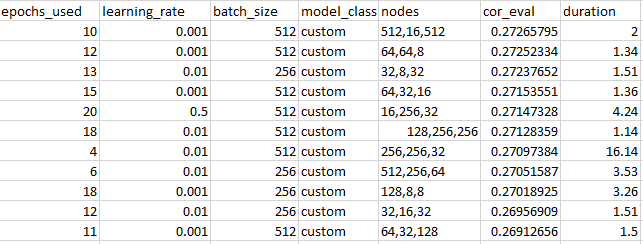
The amount of nodes in each hidden layer can be adjusted independetly, which is the architecture part of our hyperparameters. We then build a grid search for different combinations of epochs, learning rates, batch sizes and the number of nodes in each hidden layer. These are the results.
Best results:

Worst results:

Somewhere in the middle:
For comparison, the xgboost model also achieved a correlation of about 0.36.
Results
Each model we trained for 50 epochs but choosing only the model with the best score, in this case the best correlation score. The learning rate could range between 0.001 and 0.5, the batch_size could vary between 128, 256 and 512. With respect to the nodes, possible values for each hidden layer where 8, 16, 32, 64, 128, 256, 512. We used the correlation as an indicator of how good our model worked. Duration is in minutes.
Our take aways from this project: the learning rate for tabular data has to be significantly higher than for NLP and especially image recognition tasks. However, when set to high it completely destroys your results. We found a learning rate somewhere around 0.1 the best. Most of the time you do not need to train for more than 25 epochs to reach to the best possible outcome.
With respect to the architecture, we still struggle to make a clear statement.
We then repeated the experiment trying to predict whether a customer will buy or not, and the results with respect to the hyperparameters look the same. However we achieved a MSE of 0.35 while the xgboost model achieved a MSE of 0.4, so we significantly outperformed the boosted tree.
Conclusion
The main take away from this is the following: Deep Learning models can be used on tabular data while achieving results at least as good as tree-based models. When it comes to hyperparameters, the learning rate has to be significantly bigger than what you usually see in NLP or image recognition. Usually you do not need more then 25 epochs for great results.
We hope this article helped you to get your next Deep Learning project on tabular data running with a kickstart!
Lena and Lasse
